
If you open ChatGPT or Claude, you don’t need to scroll through a model picker to get started. Each has a default experience that their parent company believes represents the future of everyday AI.
OpenAI’s latest default ChatGPT-5.2 model and Anthropic’s Claude Sonnet 4.6 are designed to be fast, helpful and broadly capable, handling everything from quick emails to complex explanations without requiring technical know-how.
But how do these “just open and use” models actually compare when put to real-world tasks?
If you’re wondering which default AI assistant deserves a permanent spot in your workflow, this comparison puts them through the kinds of tasks you’re most likely to rely on — and reveals where each one excels.
Here’s a look at how the two compare through seven challenging tests.
1. Writing quality & readability
Prompt: Write a 250-word introduction for a tech article explaining why AI assistants are becoming everyday productivity tools.
ChatGPT-5.2 delivered a logically structured overview by systematically breaking down the key factors — from specific use-cases to accessibility and the redefinition of productivity — making the concept easily understandable.
Claude Sonnet 4.6 crafted a compelling narrative by opening with a vivid, almost cinematic scene to frame the rise of AI assistants as a “quiet revolution,” then grounding the technological shift in the deeply human story of reclaiming time and expanding creative potential.
Winner: Claude wins for systematically breaking down the key factors and ultimately making the concept easily understandable.
2. Structured reasoning & decision-making

Prompt: A small business owner spends 12 hours per week answering customer emails and is considering AI automation.
ChatGPT-5.2 built a persuasive case for automation by framing the 12-hour weekly task as a hidden drain on growth, then laying out the practical benefits that turn AI into a strategic lever for the business.
Claude Sonnet 4.6 answered like a useful consultant by starting with a hard cost-benefit analysis of the owner’s time, then providing a balanced, risk-aware framework that outlines where AI excels, where it could fail and a safe, practical path to start.
Winner: Claude wins for providing a decision-making framework that included a hard cost-benefit analysis, a balanced view of risks and rewards and a practical next step.
3. Explaining complex ideas simply

Prompt: Explain how large language models work to a 12-year-old.
ChatGPT-5.2 provided an age-appropriate breakdown by using the familiar concept of a phone’s autocomplete and walking through the process in simple, logical steps, ensuring a 12-year-old could easily follow the technical journey from training to response.
Claude Sonnet 4.6 made a complex topic intuitive by anchoring the explanation in the relatable metaphor of a “really well-read friend,” then gently built upon that foundation to reveal the mechanics of prediction and its inherent limitations in a clear, conversational way.
Winner: ChatGPT wins for a more relatable and cohesive story that is age-appropriate enough to be engaging for a young learner.
4. Step-by-step logic

Prompt: A freelancer earns $4,000/month and spends $2,500 on fixed expenses.
They want a $6,000 emergency fund. Create a realistic savings plan and show your reasoning step by step.
ChatGPT-5.2 acted as a meticulous financial planner by immediately clarifying a key ambiguity (pre- vs. post-tax income), running the numbers for both scenarios with clear, steps.
Claude Sonnet 4.6 took on the role of a strategic financial coach by digging deep into the often-overlooked reality of freelancer taxes and performing an honest “stress test” on the budget.
Winner: Claude wins for a more insightful response by identifying the tax burden and calculating the true disposable income.
5. Tone & style adaptability
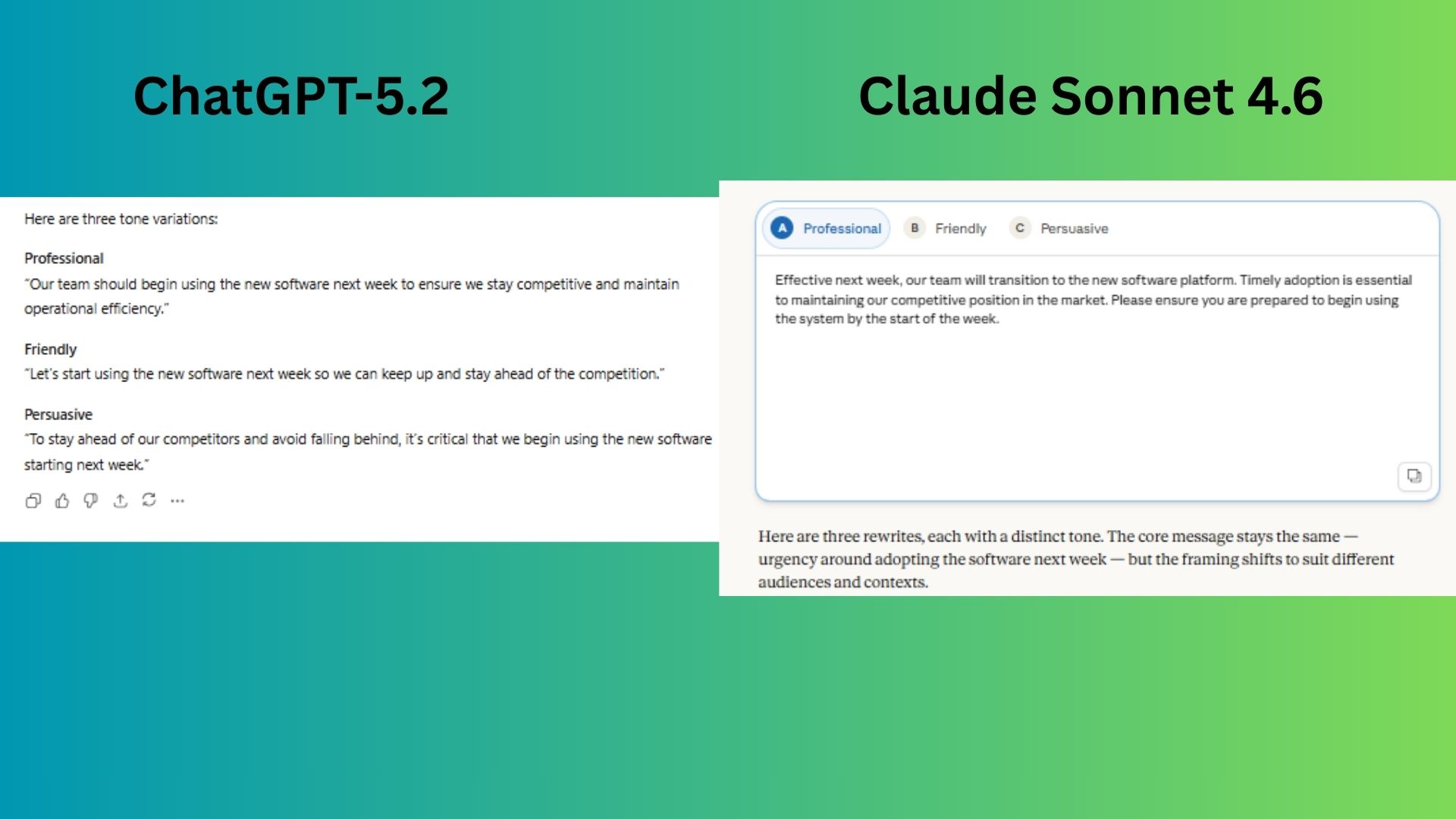
Prompt: Rewrite this message in three tones: professional, friendly, persuasive: Message: “Our team needs to start using the new software next week or we risk falling behind competitors.”
ChatGPT-5.2 took the core warning and simply filtered it through the three distinct lenses, producing variations that are grammatically correct and tonally on-target.
Claude Sonnet 4.6 interpreted the task more creatively by expanding the original message into fuller, context-rich scenarios, rather than just repeating in different ways.
Winner: Claude wins for writing responses that felt like actual usable messages that a manager would send.
6. Summarization & comprehension

Prompt: Summarize the following in 5 bullet points suitable for a busy executive: “Companies are experimenting with hybrid schedules, async communication, and four-day workweeks to balance flexibility with team cohesion.”
ChatGPT-5.2 gave a brief, but clear and scannable executive summary
Claude Sonnet 4.6 elevated the summary from simple reporting to strategic insight by reframing each bullet as an active business trend with implications. In other words, it felt like there was more effort in its summary.
Winner: Claude wins because it wrote for an executive’s mindset.
7. Critical thinking & bias awareness

Prompt: Social media algorithms often amplify extreme viewpoints. Explain why this happens and propose realistic ways platforms could reduce polarization without hurting engagement.
ChatGPT-5.2 delivered a comprehensive and structured explainer and offered a categorized list of practical solutions aimed at redesigning platform incentives without resorting to censorship.
Claude Sonnet 4.6 basically offered a masterclass in strategic analysis by explaining the mechanics and proposing solutions but also framing the entire issue with its economic reality and explicitly naming the “honest constraint” that interventions hurt engagement.
Winner: Claude wins because it showed stronger critical thinking and offered a more realistic explanation that recognizes the trade-offs platforms must balance.
Overall winner: Claude
Claude Sonnet 4.6 came out ahead almost every time by delivering responses that consistently demonstrated deeper strategic thinking, stronger real-world framing and a clearer understanding of trade-offs. While ChatGPT-5.2 performed strongly in clarity, structure and accessibility — particularly when simplifying complex ideas — Claude distinguished itself by approaching prompts with a more analytical, decision-oriented mindset.
Across writing, business reasoning and executive-level summaries, Claude’s answers often went beyond the surface task. It framed problems in practical terms, surfaced constraints and risks and provided context that would help someone make informed decisions.
Claude’s biggest advantage appeared in areas requiring judgment: evaluating automation decisions, stress-testing financial assumptions, adapting tone for real workplace use and addressing systemic issues like algorithmic polarization. In these cases, it acknowledged trade-offs and economic realities rather than presenting idealized solutions.
If you want an assistant that excels at strategic thinking, decision support and executive-ready insight, Claude Sonnet 4.6 leads.

Follow Tom’s Guide on Google News and add us as a preferred source to get our up-to-date news, analysis, and reviews in your feeds.
More from Tom’s Guide
First Appeared on
Source link






Leave feedback about this